Ancora qualcosa su K&R di cui ho raccontato qui.
Apro il libro PDF a p.13 (del PDF, è la 5 del libro) e trovo che posso ripetere un esercizio di tanti anni fa:
The only way to learn a new programming language is by writing programs in it. The first program to write is the same for all languages:
Print the words
hello, world
This is the basic hurdle; to leap over it you have to be able to create the program text somewhere, compile it successfully, load it, run it, and find out where your output went. With these mechanical details mastered, everything else is comparatively easy.
In C, the program to print “hello, world” is
main()
{
printf("heIlo, world\n");
}
Just how to run this program depends on the system you are using. As a specific example, on the UNIX operating system you must create the source program in a file whose name ends in “.c“, such as hello.c, then compile it with the command
cc hello.c
If you haven’t botched anything, such as omitting a character or misspelling something, the compilation will proceed silently, and make an executable file called a.out. Running that by the command
a.out
will produce
hello, world
as its output. On other systems, the rules will be different; check with local expert.
Adesso siccome che Linux è l’evoluzione di UNIX(allora si scriveva così; poi a dirla tutta io ero su PR1ME) quasi quasi…
Sì, proprio come mi aspettavo; manca l’include.
Ma il compilatore è smart e comprensivo, avvisa e supplisce.
Intanto provvedo, vediamo…
OK 😀
A dire il vero manca ancora una cosa: main() è una funzione come tutte le altre, anche se ha il privilegio di –dai mica devo dirvelo, mica siamo più a fine anni ’70! 🙄
In ogni caso è un warning, ritorna giusto
Pensa te! Più o meno come quando l’amico C. (non so se posso citarlo per esteso, anche perché lui sarebbe googlabile e sembrerebbe che voglia vantarmi) mi diceva dell’Odissea letta in versione originale; anche lì l’edizione originale è finita chissà dove, anzi se qualcuno sa qualcosa… Ma vale per tutti, anche –per dirne una– per The Hitchhiker’s Guide to the Galaxy.
Il PDF rivela altre sorprese (per me, sto andando sul perso): il possessore del libro dimostra di essere sorpreso dalle stesse cose che sorpresero me, per quel che ricordo ma fu davvero uno shock.
Una cosa che forse i giovani (cioè tutti quelli più giovani di me) non sanno è che ci sono state parecchie modifiche. Apriamo il PDF a p.31 (p.23 del libro) e vediamo:
visto? e se interpreto bene il possessore del libro ha annotato la nuova sintassi 😀
La Second Edition di 10 anni dopo riporta la dichiarazione attuale; a p.26 una nota ricorda la variazione intercorsa:
A note of history: The biggest change between ANSI C and earlier versions is how functions are declared and defined.
Ricordo perfettamente (quasi) 😀
OK, ricordi personali, non interessano a nessuno lo so 😀
Ma prima di chiudere ancora una cosa: ho cercato per il manuale del C del Pr1me; c’è qui: C User’s Guide Release T1.0-21.0 (1988), ma solo la scheda.
Un sito ricchissimo, dell’Università di Stoccarda ha, per Pr1me solo cose vecchie, classiche.
Forse devo cercare ancora 😉
Oggi Ieri ho scoperto una scoperta davvero meravigliosa.
Roba che io stesso stento a crederci.
E mi verrebbe voglia di cambiare nome, Indiana Juhan, o forse –più sexy– Juhan Croft; no meglio Indiana Juhan, suona meglio e poi sono vecchio e biasante circa il genere 😉 Se non fosse che devo cambiarlo in troppi posti, come non detto, però siccome sono molto orgoglioso del reperto che ho scovato voglio condividerlo urbi et orbi, anzi, di più, con tutti quanti.
Prima di tutto una nota (ci tengo): è tutto perfettamente legale, viene da Internet Archive:
The Internet Archive is a 501(c)(3) non-profit that was founded to build an Internet library. Its purposes include offering permanent access for researchers, historians, scholars, people with disabilities, and the general public to historical collections that exist in digital format.
OK, ci sarebbe parecchio da indagare su Internet Archive, chissà se troverò il tempo ma per intanto passo all’annuncio promesso. Ah! ‘ncora ‘na roba: io sono scarsamente metodico, per niente ordinato e il Linguaggio C, prima edizione in italiano del K&R ce l’avevo ma chissà dov’è finito. Ma da adesso in poi basta recriminazioni, c’è questa pagina qui: The C Programming Language First Edition 😀
Appena mi sono ripreso, appena ho smesso di URLare urlare di gioia e fare salti (sempre di) gioia e mi sono ricomposto e ri-seduto davanti al ‘puter ho scaricato la versione PDF.
Non è come quello a stampa, manca la copertina, ma sembra tutto OK 😀
Adesso vi dico anche perché dovevo fare questa ricerca, assolutamente, a ogni costo: ci sono persone che a volte si fanno trasportare dalla retorica e raccontano cose che non solo non sono vere ma nemmeno sensate; capita anche a scrittori che ammiro, da sempre; è capitato anche a DNA, il mitico Douglas Adams, in una conferenza di fronte a un uditorio selezionato ma, evidentemente, non composto da programmatori. Mi son detto che dovevo fare qualcosa, sapete com’è…
Però ricordiamoci che non è che la JVM realmente interpreta i bytecode in modo “stupido”: c’è la compilazione Just In Time (JIT) e la JVM è tanto ben fatta da poter profilare il codice a runtime per poter migliorare le ottimizzazioni in fase di compilazione JIT…
Questo potrebbe spiegare perché Java sembra battere il C. (Non prendo in considerazione il Python, e nemmeno l’Objective-C per il quale, comunque, si può fare un discorso simile a quello del C).
Passo passo, sperimentando e provando, andiamo a scoprire come stanno le cose…
Elucubrazioni e ipotesi
Intanto nel codice C ho cambiato long double in double: il double in Java è un “64-bit IEEE 754 floating point”, come il double del C. Invece il long double può essere di più. Comunque non cambia praticamente nulla: le performance continuano ad essere inferiori a quelle del Java.
Quello che ho pensato è questo: in Java l’ottimizzatore in qualche modo si accorge che tutti i calcoli da un certo punto in poi non possono che dare infinito (si va oltre le possibilità del double), per cui il ciclo più interno può essere prematuramente interrotto. Oppure: è inutile eseguire la moltiplicazione se f è già diventanto “infinito”.
Se aggiungiamo a mano questa ottimizzazione, il C torna a brillare (dovete includere math.h):
for(a = 1; a <= i; a++)
{
f *= a;
if (isinf(f)) break;
}
Si comincia a ragionare…
Oppure
for(a = 1; a <= i; a++)
{
if (!isinf(f)) {
f *= a;
}
}
Non l’ho provata ma possiamo dire che molto probabilmente sarà più lenta della versione con il break. Il vantaggio di questa versione è che permette l’esecuzione di altro codice nel caso in cui il corpo del ciclo non fosse costituito solo da f *= a.
(Ho fatto anche un’altra modifica: ho usato difftime per avere il numero di secondi… però non serve a molto quando il tutto dura meno di un secondo, e perciò ho messo time sulla linea di comando)
Si può fare di meglio: interrompere il ciclo esterno. Infatti, raggiunto un certo valore di i (chiamiamolo iMax), tutti quelli maggiori faranno in modo che il ciclo interno porti f a “inf”. Un essere umano ci arriva facilmente; ci può arrivare anche un ottimizzatore? Il codice ottimizzato avrebbe, come equivalente di alto livello C, l’aspetto seguente:
for (i = 0; i <= iMax; i++) {
double f = 1;
int a;
for(a = 1; a <= i; a++)
{
f *= a;
}
nArray[i] = i * f;
}
for (i = iMax + 1; i < MAXLOOP; i++) {
nArray[i] = INFINITY;
}
Intermezzo: un’idea sciocca
La JVM è stack based. Può essere che un modello simile in certe circostanze risulti più efficiente di uno register based? L’idea è sciocca perché non c’è modo che del codice ben ottimizzato eseguito da un hardware possa essere battuto da un interprete software (che gira sullo stesso hardware).
Ma non è proprio il caso che stiamo analizzando? No. Infatti stiamo cercando il trucco perché la tesi è che ci sia; poiché non lo vediamo, ci sembra che Java vada meglio… Ma in realtà è come se stessimo paragonando le performance del bubble sort scritto in C e Java, senza sapere che Java dietro le quinte lo sostituisce con un quick sort… (Il C non farebbe mai di questi scherzi:-D)
È possibile che le CPU stack based permettano ottimizzazioni migliori di quelle register based? Secondo questo post no:
Another advantage of the register based model is that it allows for some optimizations that cannot be done in the stack based approach. One such instance is when there are common sub expressions in the code, the register model can calculate it once and store the result in a register for future use when the sub expression comes up again, which reduces the cost of recalculating the expression.
Quindi non è che partendo dai bytecode Java si possa generare codice migliore… altrimenti i compilatori userebbero una rappresentazione intermedia stack based nella fase di ottimizzazione.
Comunque, prima di arrivare a realizzare quanto l’idea fosse sciocca, mi sono cimentato nel gioco che vedete nell’immagine.
Il disassemblato della classe (a destra nell’immagine) si ottiene con javap -c. Tutte le funzioni che vedete a sinistra hanno inline e lavorano su uno “stack” (un array) di strutture contenenti un enum che specifica il tipo (intero, double, array…) e una union.
Inutile dire che i tempi peggiorano…
real 0m6.052s
user 0m6.028s
Il codice lo potete trovare sul mio repository. (Prima o poi cambierà un po’: devo aggiungere un riferimento al post, riordinare e ripulire e commentare ecc.)
gcj
Proviamo ad usare gcj per generare un vero e proprio eseguibile da sol01.java1.
gcj -O3 --main=sol01 sol01.java
I tempi sono più o meno quelli del C. A questo punto togliamo --main e mettiamo -S per vedere il codice generato. Nessuna sorpresa: a meno di un controllo sull’indice dell’array (per poter throwareBadArrayIndex) e qualche altro dettaglio, assomiglia tremendamente a quello generato dalla versione C… del resto il compilatore sotto il cofano è lo stesso.
Dubbio: possibile che il gcc non implementi delle ottimizzazione che invece una VM è in grado di fare a runtime al momento della compilazione JIT?
(Per cercare di essere breve non lo metto :-D, ma ho fatto pure la prova con --profile-generate / esecuzione / --profile-use, giro di giostra che dovrebbe permettere al gcc di fare alcune ottimizzazione eventuali in più… Se non ho sbagliato qualcosa… Niente da fare…)
Tuttavia, non abbiamo finito di esplorare le possibilità…
clang!
Non ci stiamo dimenticando di qualcosa? gcc è un ottimo compilatore, ma non è l’unico. Proviamo con clang.
Sorpresa!
E uno sguardo al codice assembly generato rivela qual è il trucco della JVM (e di clang e di pypy e di…): sfruttare meglio le possibilità del processore della macchina che eseguirà materialmente il codice compilato JIT!
Sembra che il gcc di default preferisca generare codice “generico”.
Torniamo a gcc, ma questa volta aggiungiamo qualche opzione di compilazione e riproviamo:
Bingo.
Per non so quale motivo avevo salvato il file come sol01.java; poi, invece di rinominarlo in base al nome della classe, ho rinominato la classe… Quando si fanno le cose con criterio…↩
Qualche anno fa (sicuramente meno di 10) scoprii l’Objective-C e mi piacque molto. Ci sono almeno due cose da considerare: ① non sono mai stato un amante del C++ (potendo ho sempre provato ad evitarlo; ho iniziato ad usarlo per me stesso giusto con il C++11); ② per non ricordo quale motivo mi ero imbattuto già nello Smalltalk.
Con i template il C++ “capisce” quali funzioni servono, in base all’uso, e “genera” le funzioni apposite; nello specifico double+double, int+int, double,int. (che queste siano le “deduzioni” del C++ lo puoi vedere usando l’opzione -fdump-rtl-all del gcc e guardando il file .final generato)
p.s. tutto il resto, per lo scopo dell’articolo, è invariato: la differenza è che non siamo stati noi a scrivere esplicitamente le funzioni. Del resto se non vogliamo creare stranezze come quelle della mia miafunz (che calcola di fatto cose diverse) o se abbiamo “solo” l’esigenza della “genericità”, i template tornano utili e ci evitano copia-incolla e copertura di tutti i possibili casi (che siano effettivamente usati o no…)
Nel codice d’esempio avevo esplicitamente definito due funzioni diverse, non tanto nella signature, quanto nella loro funzionalità. Questo escludeva l’uso dei template… In realtà, non proprio… Ed è quello che volevo mostrare in questo post.
Ma prima, qualche ulteriore osservazione.
Quando la miafunz viene chiamata con argomenti il cui tipo non corrisponde a nessuno dei due casi gestiti esplicitamente, il compilatore può applicare le regole di conversione implicita e vedere se riesce a trovare qualcosa di accettabile.
Quando fate di questi esperimenti attivate un po’ di warning accessori. Compilate con
g++ -Wall -Wextra -Wconversion file.cpp -o file
oppure, per gli esempi che usano feature del C++11, con
Tutte le conversioni che possono potenzialmente dare problemi vengono annunciate con un bel warning. Il codice dell’articolo già citato vi darà un warning su
return 2.0*a + 2.5*b;
Precisamente:
warning: conversion to ‘int’ from ‘double’ may alter its value [-Wfloat-conversion]
Come ovvio: il conticino lo facciamo con double (2.5*b fa sì che b sia promosso a double) ma poi restituiamo un int. Per far sapere al compilatore che sappiamo cosa accade, possiamo mettere un cast esplicito e così salutiamo il warning.
Potete provare un’altra cosa: rendete d0 un float, invece di un double. Vi accorgerete che il compilatore è perfettamente contento: il float può essere promosso a double senza problemi, e abbiamo una versione di miafunz che accetta un double e un int come argomenti.
Provate il contrario, cioè lasciate che d0 sia double e cambiate miafunz(double,int) così:
int miafunz(float a, int b)
{
std::cerr << "double, int\n";
return static_cast<int>(2.0*a + 2.5*b);
}
(Il cast è stato aggiunto per non avere il warning cui accennavo sopra).
Succede una cosa strana: il compilatore ci dice che la chiamata a miafunz(double,int) è ambigua. In pratica sembra che non sappia decidersi se usare miafunz(float,int) o miafunz(int,int). Voi potreste pensare che la scelta sia ovvia (float), ma in realtà in tutte e due i casi la conversione può perdere qualcosa: come può il compilatore decidere? In un certo senso le intenzioni del programmatore non sono chiare: vorrebbe che fosse chiamato miafunz(float,int) perché sa che il d0 contiene un valore tranquillo per un float? O voleva troncare il numero e chiamare miafunz(int,int)?
Anche qui possiamo risolvere l’ambiguità con un cast, se siamo sicuri che non succedano cose brutte con i valori d’ingresso usati…
Template e specializzazioni
Il codice di Orlando di fatto calcola sempre a+b sugli argomenti, mentre con l’overloading esplicito dell’esempio, nel caso di int miafunz(double,int) facciamo proprio un calcolo diverso.
Ora supponiamo che ci vada bene che miafunz possa essere chiamata con tanti tipi diversi, però vogliamo che non sia a+b se viene chiamata con double e int.
Cioè vogliamo un template generico, ma con una specializzazione.
Il C++ ci permette di fornire delle specializzazioni:
#include <iostream>
template<typename T1, typename T2>
int miafunz(T1 a, T2 b)
{
return a + b;
}
template<>
int miafunz(double a, int b)
{
std::cerr << "double, int\n";
return static_cast<int>(2.0*a + 2.5*b);
}
int main()
{
double d0 = 1.0;
int di = 2;
std::cout << miafunz(d0, di) << "\n";
std::cout << miafunz(5, di) << "\n";
}
Se compilate ed eseguite, l’output sarà
double, int
7
7
Cioè miafunz(d0, di) chiama la versione specializzata per double e int, l’altra chiama uno dei template generati dal compilatore.
Un po’ di introspezione
Con il C++11 abbiamo accesso ad alcune informazione sui tipi dei template. In pratica i template sono diventati ancora più potenti e il programmatore ha ora nuove possibilità all’atto della compilazione.
Come esempio vediamo che è possibile controllare il tipo degli argomenti, sempre a compile time, e decidere di fare cose diverse… senza specializzare il template. (Nel caso dell’esempio direi che è un no-no-no: meglio usare la specializzazione!)
Nell’esempio che segue ho anche usato typeinfo (ok anche pre-C++11), che invece usa informazioni a runtime (cfr. p.es. su Wikipedia, RTTI), che di solito servono per il dynamic_cast.
#include <iostream>
#include <type_traits>
#include <typeinfo>
template<typename T1, typename T2>
int miafunz(T1 a, T2 b)
{
std::cout <<
typeid(T1).name() << ", " <<
typeid(T2).name() << "\n";
if (std::is_same<T1,double>::value &&
std::is_same<T2,int>::value) {
std::cout << "cosa?\n";
return static_cast<int>(2.0*a + 2.5*b);
}
return static_cast<int>(a + b);
}
int main()
{
double d0 = 1.0;
int di = 2;
std::cout << miafunz(d0, di) << "\n";
std::cout << miafunz(5, di) << "\n";
}
L’output dell’esecuzione è:
d, i
cosa?
7
i, i
7
Come si può intuire, d sta per double, i per int. Ma i nomi restituiti da typeid(…).name() sono specifici dell’implementazione, cioè del compilatore usato, quindi non vi ci affezionate.
Invece std::is_same è nello standard C++11 e permette di sapere se il tipo T1 è lo stesso di double (nell’esempio specifico), o qualunque altra cosa. Da type_traits abbiamo altre cosucce utili per sapere se il tipo del template ha alcune caratteristiche (provate a dare un’occhiata qui).
Nel nostro caso potremmo volere che T1 e T2 siano tipi aritmetici, perché restituiamo un int e vogliamo che + e * sia interpretabili proprio come ci aspettiamo che lo siano quando di mezzo ci sono solo numeri. In questo caso usiamo std::is_arithmetic<T>::value e nel caso la condizione non sia soddisfatta la compilazione verrebbe bloccata.
A questo scopo possiamo usare static_assert, che mettiamo come primo statement nella funzione:
Se in fase di compilazione l’assertion è falsa, il compilatore dà errore:
error: static assertion failed: non aritmetici
Fibonacci con i template
I template comportano la generazione di codice nel momento della compilazione. In un certo senso sono come le macro, solo che queste non hanno vincoli sintattici (rispetto alla sintassi del C/C++) e sono type-agnostic… anche se si possono usare dei trucchi con typeof — che gcc supporta — e poi abbiamo visto _Generic, che rende una macro non più tanto type-agnostic.
Ma niente di tutto ciò è integrato per bene con le fasi in cui il compilatore conosce il tipo di ogni “oggetto” (che è ciò che ci permette di usare auto, decltype, sizeof… std::is_arithmetic, std::is_same…) Dunque i template sono più intimamente connessi con il compilatore.
Poiché il codice dei template è generato al momento della compilazione, possiamo sfruttarlo per fare un po’ di calcoli che è inutile fare a run-time? La risposta è sì e uno degli esempi classici e tipici può essere quello della successione di Fibonacci. Esiste una definizione ricorsiva molto semplice (quella che vedete su Wikipedia).
Scrivere una funzione che calcoli l’ennesimo termine della successione è qualcosa che dovrebbe risultare semplice. Precisiamo che la ricorsione, in linguaggi che usano lo stack ad ogni chiamata di funzione e non ottimizzano il caso della tail recursion, impone dei limiti (quanto “profonda” può essere la ricorsione prima che lo stack si esaurisca?) e perciò in linguaggi come C/C++ e altri un’implementazione decente della funzione per l’ennesimo termine della successione di Fibonacci cercherà evitare la ricorsione.
Comunque. Vediamo come calcolare un numero della successione al momento della compilazione, usando i template.
#include <iostream>
template<unsigned long long N>
unsigned long long fibo()
{
static_assert(N > 1, "ops");
return fibo<N-1>() + fibo<N-2>();
}
template<>
unsigned long long fibo<0>()
{
return 0;
}
template<>
unsigned long long fibo<1>()
{
return 1;
}
int main()
{
std::cout << fibo<89>() << "\n";
}
Lo potete compilare in modo normale, ma in questo caso incappiamo nella stessa trappola della ricorsione. Però è facile, per l’ottimizzatore, “capire” come andrà finire: tutto è già lì, non c’è nessuna informazione che sia presente solo a runtime. Se aggiungete l’opzione -O2 non c’è alcuna chiamata da fare a runtime: il calcolo del numero l’ha fatto in realtà il compilatore! In pratica il codice generato si riduce a qualcosa come:
std::cout << 1779979416004714189ULL << "\n";
Infatti con l’opzione -S potete sbirciare il codice assembly generato:
subl $8, %esp
pushl $414433753
pushl $511172301
Ora lo stack (esp) punta a due parole lunghe (long word; la l della push sta per long), ovvero una quadword (robo a 64bit). L’intel x86 è un processore little endian e questo significa che “scorrendo” la memoria dagli indirizzi più piccoli a quelli più grandi, incontriamo per primi i byte, le word o le long word meno significative.
Dunque il numero a 64 bit a cui ora punta esp (lo stack) è:
414433753 ⋅ 232 + 511172301
Il numero di Fibonacci alla posizione 89 è vicino al limite per un unsigned long long. Se provate ad aumentarlo, vedrete che inizierete a non avere risultati attendibili.
Penso di dovermi fermare qui: ho fatto un post forse un po’ troppo denso.
Post scriptum
Sono uno di quegli sfigati che di default preferisce i 32bit… Compilando l’esempio con -m64 potete vedere che il codice assembly generato è un po’ più chiaro:
movabsq $1779979416004714189, %rsi
In questo modo è ancora più palese che tutti i conti sono stati fatti veramente a compile time…
Nell’articolo precedente vi ho fatto ricordare dell’Amiga, vi ho rivelato che aveva le sue espressioni regolari per fare pattern matching, vi ho indotto a (ri)leggere tre articoli di questo blog, e… (questo non lo sapete, ma) prima di pubblicarlo ho tagliato un paio di lunghi paragrafi che discettavano un po’ di linguaggi, metalinguaggi e divagazioni annesse e (s)connesse. Ora forse si capiscono meglio certe affermazioni che ho lasciato e che non si adattano benissimo al testo pubblicato; però vanno sempre bene come “scuse” anticipate per il futuro.
Dimenticavo: avevo anche detto che avremmo affrontato la prima fase: “fare” una macchina a stati finiti (FSM). Mi sono seduto e ho buttato giù un po’ di codice che ora rivediamo assieme. Lo trovate nel mio “parco giochi” su github, precisamente qui.
Le classi necessarie al gioco vivono nel namespacemFSM: visto che ho usato nomi molto poco particolari come State, Connection, Rule… non è una brutta idea metterli in un namespace ad hoc.
Introduzione
L’idea guida alla base è come viene di solito rappresentata una FSM; qualcosa come
FSM
Ogni stato è un cerchio con un “nome” (un’etichetta) e poi degli archi in uscita e in entrata. La freccia che non ha un’origine indica lo stato iniziale della macchina. Su ogni arco è indicato l’“evento” (nel nostro caso, la ricezione di un carattere) che fa passare la macchina dallo stato da cui esce l’arco allo stato in cui tale arco è entrante (insomma, nella direzione della freccia). Lo stato “a doppio cerchio” è uno stato “finale”: se la macchina, terminato il suo lavoro, si trova in uno di questi stati finali (accepting states, «stati che accettano [l’input e lo riconoscono come facente parte del linguaggio]»), significa che la stringa processata è una stringa corretta del linguaggio.
La macchina dirà allora: io, Macchina, accetto te come legittima stringa…
Vi siete già imbattuti in questa roba:
Sarebbe bello poter dire: lo stato S1 è uno stato finale, la macchina passa dallo stato S1 a S2 quando riceve uno 0, ma resta sullo stato S1 quando riceve 1, ecc.
In effetti basterebbe poter descrivere il graf(ic)o così: lo stato S1 va a S2 tramite l’arco 0, va a sé stesso tramite l’arco 1; lo stato S2 va a S1 tramite l’arco 0, va a sé stesso tramite l’arco 1; infine, lo stato S1 è uno stato finale accettabile.
Stati
Quindi per noi lo stato è un cerchio singolo o doppio con un’etichetta inscritta. Questi elementi fanno parte della sua identità e sono “passivi” e “statici”. Farne una classe è semplice
La maggior parte degli stati non sono final, da cui il default sul costruttore; ci sono due getter (per il nome e final) e un setter, nel caso volessimo cambiare final dopo aver creato l’istanza. (Se creiamo noi gli stati, serve a poco; ma vedrete dopo che la creazione degli stati può essere fatta implicitamente da un’altra classe).
Uno stato ha anche degli archi uscenti; potremmo farne uno stato consapevole del fatto che, quando riceve un certo messaggio, può dover passare il cerino ad un altro stato. Dal punto di vista della macchina nel suo insieme, lo stato con il cerino è quello in cui si trova la macchina (lo stato corrente). Con questa metafora posso dire che gli archi descrivono la “dinamica”, e ogni stato conosce la parte che gli compete, cioè i suoi archi che vanno (se valgono certe condizioni) verso un altro stato.
La classe AwareState, derivata da State1, aggiunge due cose: un metodo per stabilire un arco (onRule) e uno per iterare sugli archi. Quest’ultimo metodo è usato dal “supervisore”, cioè dal codice che fa girare la macchina: lo stato è sì “consapevole” delle sue relazioni regolate, ma non è lui a tenere traccia di chi ha il cerino e a decidere cosa farne se la regola si rivela valida o no.
Però lo stato deve fornire gli elementi affinché il “supervisore” possa decidere, e lo fa senza esporre i dettagli sul come mantiene le connessioni2: il chiamante invoca il metodo overConnectionsDo fornendo come argomento una funzione che riceve una regola (Rule) e lo stato di destinazione. Il “supervisore” applica la regola sull’input (di cui lo stato non è aware) che sta elaborando e decide se mantenere lo stato corrente o passare a quello di destinazione.
Non è un design entusiasmante… però ci permette di buttare in pentola una cosa del C++11: l’headerfunctional ci dà std::function<...> tramite il quale è facile specificare il “prototipo” della funzione che ci aspettiamo come argomento… e che potrà essere — e sarà — una closure…
bool AwareState::overConnectionsDo(
std::function<bool(const Rule*,
const std::string& stateName)> action) const
{
for (auto& c : connections_) {
if (action(c.rule, c.destState)) {
return true;
}
}
return false;
}
Usando altre due comodità del C++11 (ovvero auto e il for each che ci permette di iterare sugli elementi di una classe itarabile) passiamo in rassegna le “connessioni”; se l’action ritorna vero, usciamo a nostra volta con vero; altrimenti proseguiamo con la “connessione” successiva. Se per nessuna delle connessioni l’action ha restituito true, allora ritorniamo al chiamante con false. (Nel codice ho messo una versione alternativa di cui parlo alla fine.)
Praticamente ci aspettiamo che il chiamante usi action per segnalarci quando ha trovato una regola soddisfacente (solo il chiamante sa qual è l’input!) Se abbiamo più regole che danno true, la nostra FSM è malfatta. Non c’è nessun controllo nel codice per impedire ciò: sta a chi la costruisce non creare situazioni strane.
L’ordine delle regole va considerato arbitrario, cioè non dobbiamo far affidamento su un ordine preciso di controllo per fare magari qualche trucchetto strano. Nella specifica implementazione le regole ordinate in base alla dimensione dell’insieme di caratteri che possono soddisfarla. Quindi any, che è l’unica regola che acchiappa tutto (dunque 256 codici…), starà sempre in fondo.
L’ordinamento è fatto passando una funzione anonima (di fatto una lambda function) al metodo sort gentilmente offerto da list, che è la classe di connections_.
Per capire qual è il problema che l’ordinamento risolve, consideriamo le regole a, any, ~b controllate in quest’ordine. Non hanno molto senso: se l’input è a (1) prendiamo la prima; in tutti gli altri casi si applica any (256) e mai ~b (255). Se l’ordine fosse a, ~b, any, l’input a verrebbe catturato dalla prima, c dalla seconda e b, infine, dalla terza. I numeri tra parentesi contano i caratteri per i quali la regola è valida (un ottetto ha 256 possibili valori).
Connection
AwareState mantiene le connessioni tramite una lista (list) in cui mettiamo le coppie 〈regola, nome dello stato di destinazione〉 (struttura Connection). Ho usato il nome invece del puntatore (passato in onRule) perché c’era un meccanismo che distruggeva e ricreava gli stati e in questo modo si evitavano puntatori ballerini (dangling pointer). Naturalmente i nomi vanno risolti, e questo è a carico della classe FSM che mantiene un’anagrafe di stati e regole.
Le regole (Rule)
Un arco parte da uno stato (che è quello che lo mantiene, nella lista connections_ di AwareState) e finisce in un altro (Connection.destState) “tramite” una regola, modellata dalla classe Rule. Con “tramite” intendo dire che c’è (o ci dovrebbe essere…) una relazione tra l’avvenuta o mancata transizione e la validità dell’input rispetto alla regola in questione (e dirò anche, in alternativa, che la regola è valida per quell’input).
La regola è espressa tramite una stringa e si applica a un singolo carattere in input (passato come int). Quando dico carattere intendo in realtà byte: il codice non gestisce stringhe in codifiche multibyte. Il metodo satisfiedBy ritorna vero se il carattere soddisfa la regola, falso altrimenti.
Dal codice per satisfiedBy si capisce che le regole sono pochine: match esatto, qualunque carattere e infine match con tutto tranne un carattere specifico. Possiamo espanderle a piacere anche con l’intento di semplificare la macchina3.
Cosa accade se la regola è soddisfatta dipende dalla funzione action passata a overConnectionsDo. Il metodo viene invocato da FSM::feed.
Le regole possono venir usate più volte da diversi stati: la regola che accetta la a è sempre la stessa, sia che la usi lo stato X sia che la usi lo stato Y. Questo fatto viene sfruttato dalla classe FSM, che ha un magazzino di regole.
FSM
La classe FSM mette insieme un po’ tutte le altre classi, usandole in modo opportuno. È la classe che “rappresenta” la macchina a stati finiti ed è contemporaneamente la classe che la fa “girare”.
Per costruire la nostra macchina usiamo principalmente connect, che crea implicitamente gli stati di cui non conosce il nome; tuttavia crea stati non-final di default, per cui gli stati final vanno creati esplicitamente a parte.
L’ultima riga definisce lo stato di partenza; in questo caso non serviva perché il primo stato creato è anche quello di partenza.
La macchina m così creata è quella dell’esempio di wikipedia e serve per vedere se un numero ha un numero pari di 0.
Come usiamo questa macchina? Abbiamo due modalità principali.
Una è quella passo-passo: le diamo in pasto dei caratteri (tramite il metodo feed) e lei si comporta di conseguenza, cambiando il suo stato (oppure no…). Quando abbiamo finito possiamo sapere se la macchina è in uno stato final usando il metodo accepted(). Se vogliamo riusare la macchina per un’altra sequenza, dobbiamo riportarla allo stato iniziale (metodo rewind).
L’altra modalità prevede di far girare la macchina su una stringa (run). Questo metodo parte sempre dallo stato iniziale, ma al termine lascia la macchina nello stato dove l’input l’ha condotta; perciò dovete chiamare rewind se dopo un run volete usare feed con la macchina nello stato iniziale.
Il metodo run ha due modi diversi di funzionamento: uno strict, in cui l’assenza di una regola che gestisca l’input interrompe il processamento e restituisce false (però la macchina potrebbe essere ferma su uno stato final… sta al chiamante decidere che fare…); un altro in cui ogni carattere per il quale non c’è una regola lascia la macchina indifferente (si passa al carattere successivo rimanendo nello stesso stato). Il default è la versione “rilassata”; si può cambiare chiamando il metodo strict(true).
Il metodo feed è un po’ il cuore dell’esecuzione. Dopo un breve preambolo per assicurarsi che ci sia uno stato iniziale e quello corrente, abbiamo una bella closure passata al metodo overConnectionsDo dello stato corrente.
Se andate a vedere il codice di overConnectionsDo, vedete che è un ciclo sulle “connessioni”, cioè sulle coppie 〈regola, stato destinazione〉. È quello che la funzione riceve in ingresso (r e s). Oltre agli argomenti, la funzione “cattura” c, next_current e this. Poiché abbiamo bisogno di cambiare next_current, lo catturiamo per riferimento (this è un puntatore e quindi automaticamente con this->states_ facciamo riferimento all’istanza e non ad una sua copia).
Se il carattere c soddisfa la regola che lo stato ci ha passato, allora il prossimo stato sarà quello specificato da s, posto che esista. Alla fine della giostra matched sarà vero se c soddisfa almeno una delle regole r, e sarà falso altrimenti (se nessuna regola è stata soddisfatta).
Verifichiamo!
Il codice testFSM.cpp crea alcune FSM e le mette alla prova. In particolare ho creato la FSM corrispondente al pattern #?.info… Il pattern non richiede che dopo .info non ci sia altra roba. Sapete modificare la FSM in modo che la stringa da verificare debba finire esattamente con .info? (Con le RE ciò equivale a .*\.info$4).
Trovate anche la macchina per la grammatica a(ab)n e quella per riconoscere i codici 12A45 o 22B48 (cfr. Macchine a stati 2). Potete aggiungere tutti i test che volete per verificare che si comporti come vi aspettate… Se trovate un bug, sono qui per schiacciarlo… sempre tempo permettendo!
Sul codice
Non ci dovrebbero essere cose particolarmente difficili.
Ho cercato di mettere un minimo di enfasi su ciò che personalmente trovo più interessante nel C++11, ovvero le funzioni che stanno guadagnando il posto di cittadini di prima classe e ci permettono di adottare un po’ del paradigma funzionale. A tal scopo, oltre a functional, ho incluso algorithm per riscrivere il codice di overConnectionsDo usando std::any_of, che restituisce vero se per uno qualunque degli elementi il predicato ritorna vero (qui il predicato è data dalla nostra action, che dobbiamo però wrappare in un’altra closure per “adattare” gli argomenti5).
Un’altra cosa che torna comoda è poter demandare al compilatore l’ingrato compito di “capire” il tipo giusto di un dato, visto che lui può dedurlo; alle volte non è solo ingrato, ma anche piuttosto complicato (non è il caso del codice della FSM, ma il discorso è generale). Su questo versante ho usato due novità: auto e decltype, che vedete nel frammento sopra. Sconsiglio l’uso di decltype come l’ho usato io: l’ho fatto solo per farvi vedere che, volendo, si può fare… (a mano avremmo scritto const Connection&).
Infine, tutto vive in due file soltanto, FSM.cpp e FSM.hpp. In teoria sarebbe più carino se avessimo State.cpp, AwareState.cpp, Connection.cpp, Rule.cpp, FSM.cpp e relativi .hpp. Ma viste le dimensioni del tutto, non credo che sia un peccato troppo grande aver fatto un nunico malloppo.
Questo se state nella root del progettino (un livello sopra src). Forse ci aggiungerò un Makefile in futuro.
Poteva esserci anche una sola classe State, che fosse già anche consapevole, visto che State normale non è usata… Potete provare come esercizio ad eliminare State incorporandola direttamente in AwareState (poi potete rinominarla in State). È andata così perché prima è uscita la classe, piuttosto ovvia, State e solo dopo mi sono trovato a dover scegliere come rappresentare le “connessioni” tra i diversi stati. Dalla scelta fatta è nato l’AwareState…↩
Questo perché per progetto le “connessioni” sono informazioni che lo stato tiene con sé, diventando “stato consapevole”, AwareState. Si poteva fare diversamente, forse meglio: una classe che descriveva tutta la FSM: dallo stato Si si va allo stato Sj quando la regola Rn è valida… ecc. Il “supervisore” non avrebbe fatto altro che leggere questa descrizione e agire basandosi su di essa e sull’input. Invece per ciascuno stato l’informazione che serve al “supervisore” è nello stato stesso, per cui c’erano almeno due opzioni: un getter per ottenere la lista degli archi uscenti (connections_), o un metodo che invoca una funzione su ciascuna connessione trovata — ogni “connessione” è una “regola” e uno stato destinazione.↩
Per esempio: se il carattere è in un elenco (immaginate [0-9]), salta allo stato Sn. Dobbiamo fare un arco per ciascun carattere; se la Rule consentisse il match con un elenco, ci risparmieremmo un po’ di archi.↩
Invece nel caso dei pattern Amiga è implicito, nel senso che il match è sempre esatto; con le RE è come se scrivessimo sempre ^...$ (dove ... rappresenta il resto della RE); quindi in realtà il pattern che la FSM implementa è #?.info#? e non #?.info.↩
Si potrebbe usare std::function<bool(const Connection&)> e risparmiarci un livello: il predicato sarebbe direttamente action.↩
Sono un Amighista, lo confesso. L’Amiga era un computer molto serio, a dispetto di ciò che tanti credono dal momento che il suo successo commerciale era dovuto principalmente ad alcune capacità che lo rendevano assai appetibile nel mondo ludico. Oltre all’hardware custom (che oggi fa sorridere ma all’epoca era incredibile…) c’era un sistema operativo straordinario.
Non voglio parlarvi dell’AmigaOS in generale: mi aggancio ad alcuni vecchi articoli di questo blog che parlano di regular expression e macchine a stati finiti, e con il pretesto cerco di implementare il pattern matching usando le regex nella variante messa a disposizione dall’Amiga tramite la libreria di sistema dos.library.
Sull’Amiga si parlava proprio di pattern matching: vedete per esempio la sezione 7-31 del manuale Using the System Software v2.05, che potete trovare su archive.org in vari formati tra cui DJVU.
Rileggere questi post (o leggerli se non li avete mai letti) non vi farà male:
Spero che le mie scarse capacità didattiche e la mia prolissità non vi ammorbino troppo. Se notate errori di varia natura (che non siano frutto di necessarie semplificazioni) o avete suggerimenti, li ascolterò… tempo permettendo.
Questo articolo è solo di apertura e non c’è veramente carne al fuoco.
Pattern matching su Amiga
Pare che ci siano circa 7000 linguaggi nel mondo, ma quelli che siamo in grado di elencare e di cui sappiamo l’esistenza sono una misera frazione.
Le regular expression più note sono in pratica tre e sembrano varianti/estensioni di una base comune: POSIX semplici, estese e PCRE (Perl Compatible Regular Expression).
Ma un tempo c’era pure l’Amiga e anche lì c’era l’esigenza di avere delle regular expression per fare del pattern matching (chiaro, no?) Un uso caratteristico era nei file requester1.
Un file requester della libreria di sistema asl.library
Il file requester nell’immagine è dell’AmigaOS4, ma comunque c’era pure nelle versioni precedenti (fornito allora come “ora” dalla libreria di sistema asl.library), anche se magari meno gratificante esteticamente; per i più esigenti c’erano altre possibilità fornite da toolkit come MUI o ReAction.2
Il punto comunque è che in questi file requester tipicamente si metteva di default il pattern per nascondere i file .info, che sono dei file del Workbench (il “desktop” e l’explorer o il finder dell’Amiga) contenenti l’icona ed eventualmente alcune metainformazioni associate. Niente che di solito l’utente voglia vedere quando richiede l’elenco dei file contenuti in una cartella, che su Amiga si chiamava drawer (cassetto) o directory (schedario).
Per questi scopi il glob è più popolare, è un po’ più alla portata di tutti (mentre moltissimi utenti non sanno nulla delle regular expression): se una finestra di dialogo di un programma di grafica ci chiede di scegliere un file, molto probabilmente applicherà diversi “glob”, uno per ogni formato che capisce: *.jpg, *.png ecc.3
Il pattern (Amiga) per nascondere i .info è, come potete vedere dall’immagine, ~(#?.info): il pattern #?.info selezionerebbe tutti i file terminanti in .info. Il ~ nega e le parentesi raggruppano, sicché ~(#?.info) seleziona tutti i file che non soddisfano il pattern #?.info, cioè che non terminano con .info.
Avrete intuito (forse) che #?, espresso nella lingua delle regular expression più note, è .*. Su Amiga ? significa “qualunque carattere”, dunque equivale al punto, e # è il quantificatore (ciò che segue compare 0 o più volte), dunque equivale all’asterisco. Notiamo anche che l’ordine è invertito: su Amiga diciamo prima quante volte compare ciò che segue, mentre nelle RE il quantificatore viene dopo.
Il problema che ci poniamo non è la traduzione tra sintassi diverse di RE o pattern “equivalenti”: vogliamo costruire una macchina a stati finiti per matchare una stringa a partire dai pattern in stile Amiga.
Notate una cosa: una volta che abbiamo la nostra macchina a stati finiti, ci possiamo disinteressare delle sue origini, cioè da dove siamo partiti per generarla: siamo partiti da #?.info? O da .*\.info? O da *.info? O l’abbiamo scritta a mano?
Per incuriosirvi… (spero di avere il tempo e la voglia: che non diventi del vaporware, insomma!)
Il problema può essere decomposto in due parti. La prima è poter definire programmaticamente una macchina a stati finiti, ed è quello che volevo provare a fare nella prossima puntata. Fatto ciò, dovremo risolvere l’altro problema: generare la macchina a partire dal pattern4.
L’idea che voglio seguire per la FSM è questa: definire gli stati e poi “unirli” tra di loro, specificando in quale circostanza (ovvero in seguito a quale “evento”) si passa da uno stato all’altro — l’esempio terrà sempre a mente l’uso specifico delle espressioni regolari e affini, sicché gli “eventi” sono in realtà i caratteri letti dall’input. Potremo poi dare in pasto alla macchina a stati così definita la stringa da controllare.
Una volta che abbiamo questi mattoncini, dovremo implementare un algoritmo che ci consenta di generare la macchina a stati a partire dal pattern: tornerà in gioco il pattern matching Amiga, tanto per prendere le distanze dalle RE note, troppo famose… e anche perché sennò che ne ho parlato a fare?
Due cosette che è bene tenere a mente:
non ho alcuna pretesa di rigore formale teorico (non ne sarei nemmeno capace) — se avete rimostranze sulla terminologia, suggerimenti per evitare fraintendimenti con il mondo accademico e/o settoriale, o perle di saggezza in generale, elargitele, ma tenete a mente che semplificare e comunicare alle volte significa mentire consapevolmente…;
alcuni aspetti (anche pratici) non saranno curati, per questioni di tempo e proporzioni — insomma, non vi aspettate del codice perfetto, con un design ben pensato, ecc… tuttavia, se mi fate notare o se noterò da me erroracci e/o antipattern vergognosi, proverò a trovare il tempo di coprire le tracce correggerle.
Dubitate, pensate, esplorate, non vi fermate, ricominciate.
Qui metterò il link alla prossima puntata non appena avrò avuto il tempo di scriverla:
«I requester sono delle sottofinestre temporanee usate per confermare azioni o selezionare opzioni» (tradotto da ASL Library, About Requesters. Sono insomma delle finestre modali.↩
Nelle versioni più recenti del sistema (ma prima di AmigaOS4), Amiga aveva introdotto il BOOPSI — Basic Object Oriented Programming System for Intuition — negli “ingranaggi” di Intuition (appunto). Questo facilitò la nascita di toolkit che si integravano bene con Intuition, sia dal punto di vista dell’utente quanto del programmatore (che comunque, come al solito, ha vita sempre un po’ più difficile…) Potete pensare a BOOPSI come alle fondamenta per la costruzione delle classi di oggetti dell’interfaccia.↩
Seguendo l’incauta consuetudine secondo la quale ciò che viene dopo l’ultimo punto del nome di un file sia sufficiente ad identificarne il formato.↩
#include <iostream>int miafunz(int a, int b)
{
std::cerr << "int, int\n";
return a + b;
}
int miafunz(double a, int b)
{
std::cerr << "double, int\n";
return2.0*a + 2.5*b;
}
int main()
{
double d0 = 1.0;
int di = 2;
std::cout << miafunz(d0, di) << "\n";
std::cout << miafunz(5, di) << "\n";
}
Lo compiliamo e lo eseguiamo:
Quello che accade dietro le quinte è che il compilatore in realtà genera due funzioni diverse e “capisce” qual è quella giusta da chiamare basandosi sul tipo degli argomenti.
Per il programmatore è tutto trasparente, mentre compilatore e linker hanno una gatta da pelare in più. Il problema è questo: le due funzioni sono in realtà diverse, pezzi di codice diverso, e ciascuna deve avere associato un simbolo diverso1, anche se il programmatore usa solo il nome che ha deciso (miafunz).
Se non è definita e imposta un’ABI specifica per tutte le implementazioni del C++, ci possono essere “incomprensioni” perché ogni compilatore “decora” i nomi delle funzioni come meglio crede. (Cfr. name mangling)
Detto altrimenti: il compilatore C++ si deve inventare due nomi per le due funzioni, laddove noi usiamo un unico nome. È abbastanza ragionevole ipotizzare che i nuovi nomi siano costruiti a partire dal nome da noi scelto, secondo un certo schema2 — ma non è affatto necessario che sia così. Nel caso di g++ (4.7.2),
ed è lo stesso con clang++ (3.0), per la cronaca. È buono che ci sia una certa convergenza, ma purtroppo in realtà non possiamo farci affidamento. Invece di spiare l’ELF potete dire al g++ di fermarsi alla generazione del codice assembly (opzione -S) e dare uno sguardo ai simboli usati.
Il C non ha di questi problemi
Il C non ha di questo problemi perché non permette l’overloading. Se scrivete
#include <stdio.h>int miafunz(int a, int b)
{
fprintf(stderr, "int, int\n");
return a + b;
}
int miafunz(double a, int b)
{
fprintf(stderr, "double, int\n");
return2.0*a + 2.5*b;
}
int main(void)
{
double d0 = 1.0;
int di = 2;
printf("%d\n", miafunz(d0, di));
printf("%d\n", miafunz(5, di));
return0;
}
il compilatore si ribella,
perché stiamo ridefinendo una funzione (ho usato gcc 5.2 perché evidenzia meglio gli errori, in stile clang). In C i simboli delle funzioni devono essere unici (all’interno del loro campo di visibilità3).
Potremmo scrivere
int miafunz_ii(int a, int b)
{
fprintf(stderr, "int, int\n");
return a + b;
}
int miafunz_di(double a, int b)
{
fprintf(stderr, "double, int\n");
return2.0*a + 2.5*b;
}
ma poi starebbe a noi scegliere la funzione “giusta” per gli argomenti giusti. Fattibile, ma potenziale fonte di errori e comunque appesantisce la lettura (e la scrittura…). Un esempio più concreto è quello di certe funzioni matematiche per le quali in effetti nella libreria esistono diverse versioni a seconda del tipo di argomenti usati e restituiti; p.es. sin (double), sinf (float), sinl (long double).
Il C11 è venuto incontro a questa esigenza tramite una macro, _Generic, il cui uso però risulta limitato, cioè non dà la stessa elasticità dell’overloading del C++: in pratica è utile solo per tgmath.h (type generic math).
Quando le persone sentono Fortran credono di essere tornati indietro nel tempo: è un linguaggio vecchio, ormai in disuso, è brutto, ecc… Non è così. Di sicuro è “di nicchia”. Ma comunque, a differenza di altri linguaggi di quell’epoca, è andato avanti e si è ammodernato. L’ultima versione dello standard è il Fortran 2008, ma è pianificato il Fortran 2015.
Una delle caratteristiche del Fortran moderno sono le interfacce. In pratica il Fortran ha lo stesso problema che il C(11) ha in parte risolto con _Generic; però la soluzione è molto più… generica!… elastica, elegante e (a mio immodesto avviso) intelligente.
Dettagli sintattici a parte, il programmatore non lascia al compilatore l’onere di generare i nomi delle funzioni: egli scrive le diverse funzioni come deve (p.es. miafunz_di, miafunz_ii) e specifica che miafunz è un’interfaccia a quelle funzioni (il compilatore di solito è nelle condizioni di poter dedurre da sé la funzione giusta in base al tipo degli argomenti, proprio come avviene per il C++; nei casi in cui non dovesse essere così, nell’interfaccia dovremmo specificare per intero gli argomenti e i loro tipi).
Riciclo di nuovo un esempio da un altro blog; nell’esempio my_sum è definita come interfaccia per le funzioni my_sum_r, my_sum_i, ecc…
A codice oggetto generato, non è sempre necessario. Per esempio nell’esempio specifico in teoria non c’è nessun bisogno che i simboli delle funzioni rimangano, perché di fatto non ci interessa esportarli. Tant’è che tali simboli possono essere rimossi, per esempio con strip. Il discorso sarebbe diverso se stessimo scrivendo del codice che deve essere linkato (una libreria statica o dinamica, per esempio).↩
Una soluzione ragionevole (perché intellegibile) è quella di codificare nel nome della funzione i tipi degli argomenti; vediamo infatti che miafunz(double,int) diventa _Z7miafunzdi e miafunz(int,int) diventa _Z7miafunzii.↩
O «confine entro cui sono visibili». È la mia traduzione approssimativa di scope. Non voglio affrontare questioni linguistiche sottili, ma la traduzione “visibilità” non mi sembra del tutto corretta. La visibilità (visibility) è la proprietà di essere visibili (la proprietà di un oggetto di poter essere visto); il termine scope fa riferimento a quanto è “estesa” questa proprietà, cioè fin dove vale o non vale per un determinato oggetto; dunque si riferisce all’“area di pertinenza” di una proprietà (in generale, e della visibilità nello specifico). La traduzione “visibilità” di per sé non veicola l’idea di “estensione”. Prendiamo per esempio la frase «the name must be unique in its scope». La traduzione «il nome deve essere unico nella sua visibilità» non corrisponde all’originale; in italiano siamo costretti ad usare una perifrasi: «il nome deve essere unico» «all’interno dell’ambito in cui è visibile», o «all’interno dell’estensione della sua visibilità», o «entro la portata della sua visibilità», o «nel suo campo di visibilità» (forse l’opzione migliore), o altre espressioni simili. Per quanto mi riguarda, in casi come questi non ho nessun problema ad usare termini inglesi nell’italiano settoriale.↩
Come primissimo e rapido contributo minimo a questo blog, mi aggancio a Errore! manco 2+2 sa fare per mostrarvi come lo farei in C; le prime 3 soluzioni viste su StackExchange mi sembrano insoddisfacenti.
#include <stdio.h>#define a a=5,bint main(void)
{
int a = 2 + 2;
printf("%d\n", a);
return0;
}
Sfrutto le macro, che secondo qualcuno andrebbero evitate il più possibile e sono pericolose: questo esempio mostra che effettivamente possono creare qualche problemino… Ma il C ci convive da sempre e io continuo a difenderle — ma sono anche tra quelli che non inorridiranno il giorno in cui avremo import <stdio.h> o qualcosa di simile.
Post scriptum
Per qualche misterioso caso c’era un erroruccio nella define… nessuno lo notò… Per fortuna su StackExchange non ho fatto lo stesso errore ;-D
A una certa ora (comunque troppo presto) mi accorgo che non capisco più quello che tento di fare, allora chiudo tutto e smetto. Poi capace che vado anche a dormire presto, come ieri. E mi capita di sognare che sono al Paradiso della Brugola che sto movimentando tweets con un hand-truck (sì, lo so che da noi non si chiamano così ma il sogno era quello). Sì lo so che non si usa un carrello per spostare i tweets (spostarli dove?) ma nel sogno era così. E il sogno è mio (quello) 😉
Mi sono svegliato con la convinzione che dovevo riprendere un argomento discusso su Facebook e del quale ho anche fatto un post: Sul calcolo di base elevato esponente.
Colpa anche di GLF, Gianluigi Filippelli, che l’altro giorno ha messo su Schema per affrontare il calcolo di un esponenziale.
Prima o poi ritorno sullo schema di GLF, ma intanto continuavo a chiedermi come si deve intendere il segno del numero da elevare a potenza.
Cioè quando scrivo: r = b ^ e cosa intendo davvero? b è negativo di suo o invece sto calcolando un’espressione che deve dare un risultato negativo?
Secondo me –potrei sbagliare, anzi aiuto!!!– nei casi normali (ahemmm…) mi viene da pensare che sia r = s * b ^ e dove s è il segno.
In queste condizioni ecco il programmino (elementare; non so se esista una funzione tipo sign(), la mia riga 6), pows.c:
#include <stdio.h>
#include <math.h>
double pows(double n, double e) {
double s;
s = ((n - fabs(n)) >= 0.0 ? 1.0 : -1.0);
return(s * pow(fabs(n), e));
}
int main () {
double bp = 2.0, bn = -2.0,
e = 7.0 / 3.0;
printf("%lf ^ %lf = %lf\n", bp, e, pows(bp, e));
printf("%lf ^ %lf = %lf\n", bn, e, pows(bn, e));
return(0);
}
Niente piùnan. Sensato? (Help!!!)
Nota: Il Paradiso della Brugola esiste davvero; e io che mi pensavo che era una cosa di Jane e –prima ancora– di Matteo e invece no, c’è. Se siete di quelle parti provatelo. E dite che vi mandiamo noi, Jane, Matteo e me. Nèh! (come si dice “nèh” in milanese?) 😀

 Ancora qualcosa su K&R di cui ho raccontato qui.
Ancora qualcosa su K&R di cui ho raccontato qui.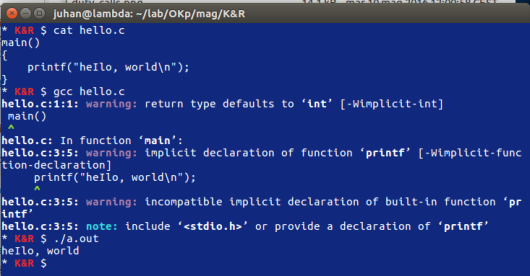
























 A una certa ora (comunque troppo presto) mi accorgo che non capisco più quello che tento di fare, allora chiudo tutto e smetto. Poi capace che vado anche a dormire presto, come ieri. E mi capita di sognare che sono al Paradiso della Brugola che sto movimentando tweets con un hand-truck (sì, lo so che da noi non si chiamano così ma il sogno era quello). Sì lo so che non si usa un carrello per spostare i tweets (spostarli dove?) ma nel sogno era così. E il sogno è mio (quello) 😉
A una certa ora (comunque troppo presto) mi accorgo che non capisco più quello che tento di fare, allora chiudo tutto e smetto. Poi capace che vado anche a dormire presto, come ieri. E mi capita di sognare che sono al Paradiso della Brugola che sto movimentando tweets con un hand-truck (sì, lo so che da noi non si chiamano così ma il sogno era quello). Sì lo so che non si usa un carrello per spostare i tweets (spostarli dove?) ma nel sogno era così. E il sogno è mio (quello) 😉
 Nota: Il Paradiso della Brugola esiste davvero; e io che mi pensavo che era una cosa di
Nota: Il Paradiso della Brugola esiste davvero; e io che mi pensavo che era una cosa di 
