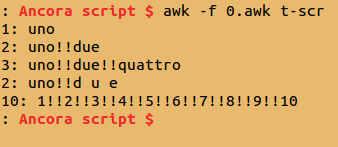
È fattibile uno script che dato un file di testo faccia come da titolo? Uh! vediamo 😯
Un compito semplice e conosciutissimo –anche da me– esegue la prima parte, eccolo:
#!/usr/bin/awk -f
!a[$0]++Funziona perfettamente, esempio:

Proprio OK, eliminate tutte le doppie.
Ma a me servirebbe un’altra cosa: le righe vuote voglio tenerle tutte. Questo mi serve per le raccolte di Visto nel Web, AI e innovazioni e cit. e loll. dove le righe vuote separano le descrizioni dei link. OK, dovrei riscrivere tutto ma adesso va di moda –funzionalmente– essere lazy… 😉
AWK è uno dei miei linguaggi preferiti da sempre; appena misi le mani su un ‘puter Unix feci le fotocopie dei manuali di sh, vi, sed e AWK. Per Fortran e C avevo già tutto, cioè no, qualcosa: il K&R troppo sintetico, il TAB da aggiustare per il Fortran, le opzioni di compilazione, mica c’era Stak Overflow allora 😐 E neanche il Web. E anche i BBS sarebbero venuti dopo (con l’accoppiatore acustico (modem) a 2400 BPS). OK, sono OT 😐
Non so se la soluzione cui sono giunto sia bella, ma mi sembra funzioni e per adesso è questa (ndtv0):
#!/usr/bin/awk -f
{ if ($1 ~ /^\#:/ || $0 == "")
{ print }
else
{ { if (!a[$0]++) print }
}
}
A dirla tutta c’è una riga vuota di troppo ma questo non da fastidio al mio caso. Questo però è solo il primo passo. Devo salvare l’output in un file e confrontarlo con quello di input. Se i due coincidono lo cancello altrimenti cancello l’originale (no, lo rinomino con estensione .bak) e rimonimo l’output con il nome dell’originale (file ndtv1).
#!/bin/bash
ndtv0 $1 > $1".tmp"
diff -s $1 $1".tmp"
R=$?
if [ $R == 1 ]; then
echo "aggiorno"
mv $1 $1".bak"
mv $1".tmp" $1
else
rm $1".tmp"
fi
Ripetendo il comando il file dovrebbe già essere OK:

OK, non resta che abilitare ndtv0 e ndtv1 (dopo averlo spostato in ~/bin o in un’altra dir presente in $PATH).
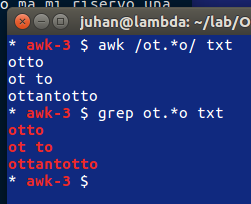
Ma è una cosa tutt’altro che finita. Nello script AWK ho inserito di tenere le righe delle categorie, quelle che iniziano con #: (notare che # è speciale e dev’essere baskslashato).
Il file risultante da questo filtro potrà risultare con righe fuori posto, come le due righe vuote consecutive dell’esempio. Ma qui continuo con un linguaggio normale (Python in questo caso) e il lavoro diventa più normale, noioso. Un collega di una volta (quasi 30 anni fa) dissente dal mio insistere con roba tipo AWK. Sono vecchio (ma anche lui, anagraficamente). Forse è arrivata per me l’ora di smettere, anche perché i blog sono passati di moda 😐
⭕






























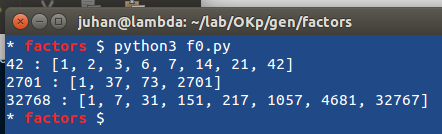
 OK, sono indaffarato su altre cose ma non posso abbandonare Racket, il mio linguaggio di programmazione preferito (con zilioni di altri, tutti pari-merito).
OK, sono indaffarato su altre cose ma non posso abbandonare Racket, il mio linguaggio di programmazione preferito (con zilioni di altri, tutti pari-merito). Per passare il numero da fattorizzare sulla riga di comando si può fare:
Per passare il numero da fattorizzare sulla riga di comando si può fare: E il comando si può –ovviamente semplificare:
E il comando si può –ovviamente semplificare:
 La prima ottimizzazione si ottiene considerando solo i numeri compresi nell’intervallo
La prima ottimizzazione si ottiene considerando solo i numeri compresi nell’intervallo  Meglio ancora, i divisori non possono essere maggiori della radice quadrata del numero; output come il caso precedente (ho modificato il range del
Meglio ancora, i divisori non possono essere maggiori della radice quadrata del numero; output come il caso precedente (ho modificato il range del  Eh, sì 😀
Eh, sì 😀 Molto meglio usando
Molto meglio usando 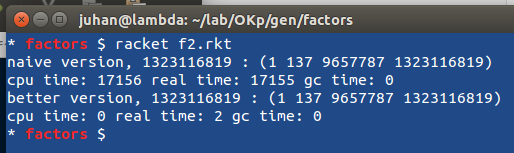 Ma esiste un modo ancora migliore, usare la funzione
Ma esiste un modo ancora migliore, usare la funzione 
 Sono in ritardo su tutto; devo ancora finire due cose per domani ma devo proprio dire una cosa. Anche perché riguarda in qualche misura quello che devo fare per domani.
Sono in ritardo su tutto; devo ancora finire due cose per domani ma devo proprio dire una cosa. Anche perché riguarda in qualche misura quello che devo fare per domani. Ma il motivo vero di queste note è un altro, anzi più di uno.
Ma il motivo vero di queste note è un altro, anzi più di uno. Un post piccolo piccolo ma c’è una cosa che devo proprio dire: è una grande soddisfazione quando fai qualcosa che viene usata e apprezzata. Specie se funziona al primo tentativo, anche senza la mia assistenza 😛
Un post piccolo piccolo ma c’è una cosa che devo proprio dire: è una grande soddisfazione quando fai qualcosa che viene usata e apprezzata. Specie se funziona al primo tentativo, anche senza la mia assistenza 😛